刚刚在某社交平台上刷到一组对话,挺有意思。
某位知名时政博主发帖说,他把今年的高考数学卷丢给 Claude 来做,结果惊掉下巴:选择题第 10 到 14 题连续做错,证明题也错了好几道,算下来竟然不及格。更让他绝望的是,他让模型回头核查,它折腾半天,只揪出其中一道题的错,其余照错不误。他感慨,这实在有点“侮辱 AI”。
底下有条神回复,把我看乐了:
爷爷,最聪明的版本是 Opus 4.8,不是 Sonnet;而且你得把 effort 调成 Max。再这么用下去,您这辈子怕是要被 AI 淘汰咯。
一句玩笑,却精准戳中了这个时代很多人使用 AI 的误区。更妙的是,发帖人截图右下角写得清清楚楚:模型是 Sonnet 4.6,effort 是 Low。一份高考压轴卷,他偏把两个旋钮都拧到了最省力的一头,然后回头怪 AI 不及格。
这事让我又想起卡尼曼那本《思考,快与慢》。他说人脑里住着两个系统:系统 1 快、自动、凭直觉,张口就来;系统 2 慢、吃力、讲逻辑,要一步一步算。过去,这两套系统是天生的,藏在颅骨里,由不得你挑。如今,AI 把它们做成了明面上的开关,而且是两组开关。
那条回复的高明,正在于它一次点中了两个旋钮:一是换更强的脑子,二是把努力程度拉满。这也是我想聊的核心问题:AI 时代,我们到底该如何选择模型,又该如何选择思考程度?
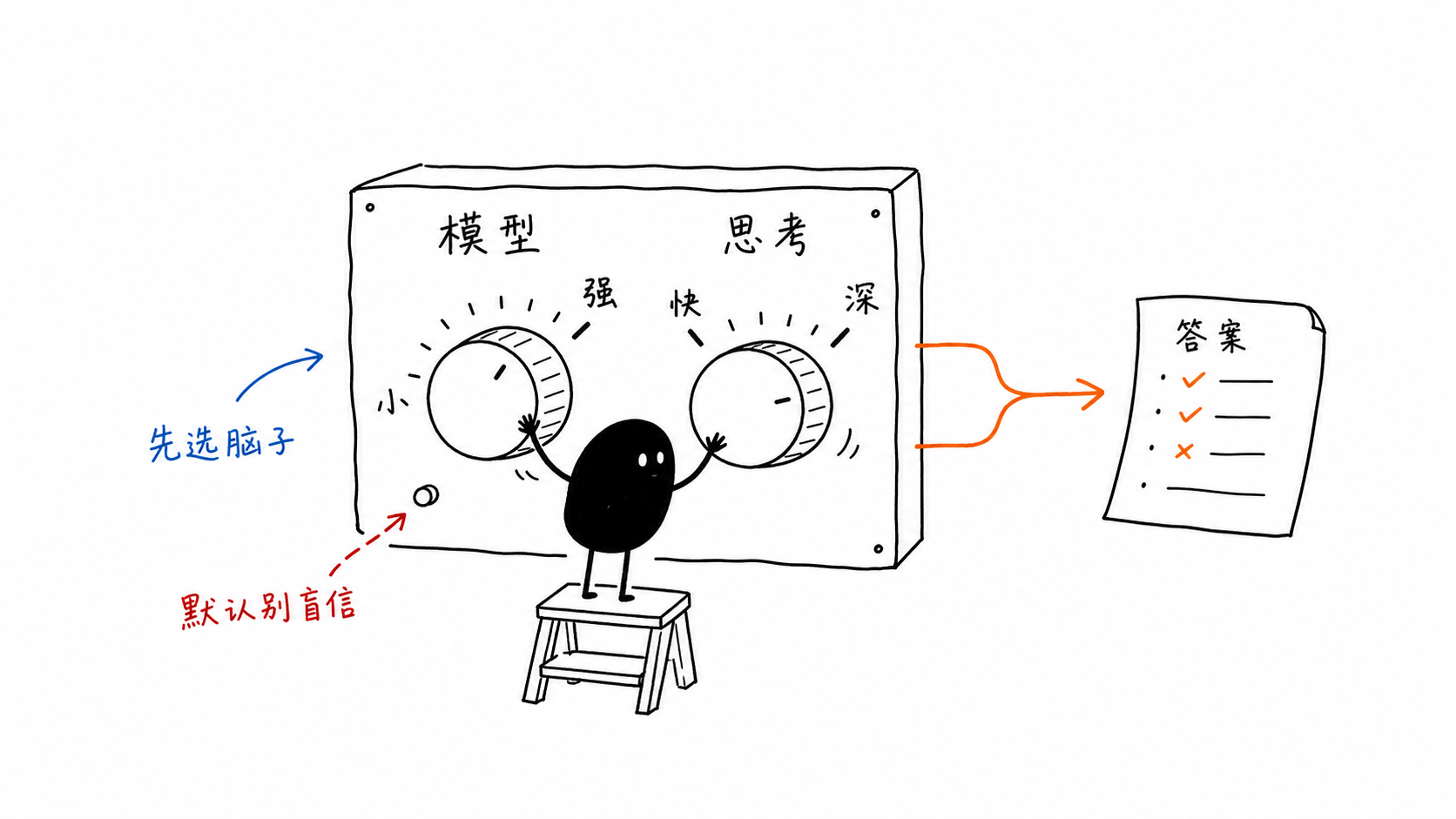
第一个旋钮:让它想多深
很多人打开 AI 工具,习惯性使用“快速”模式。它当然快,但那是一种很接近系统 1 的快:直觉先冲出来,答案先端上桌,至于里面有没有矛盾、有没有错漏、有没有经得起复核,往往要到事后才知道。
快速模式像系统 1。
模型最让人头疼的“幻觉”,也就是一本正经地编出通顺却虚假的内容,很大程度上就是这种快的产物。它把语言顺下去了,把逻辑的样子做出来了,但未必真的回头查过、反着证过、自己审过。
所以,在大多数文书、代码、法律检索、复杂推理这类要紧的工作上,默认快速模式并不一定合适。更稳妥的做法,是主动打开深度思考或高 effort 模式,让模型多走几步:先拆题,再推理,再复核,再给结论。
这正是系统 2 在替系统 1 兜底。
深度思考像系统 2。
所谓“想得深”,本质上不是让模型变聪明,而是让它在当前能力范围内,愿意花更多功夫。
它会更慢,也会更贵。深一档,就多烧一份算力,多等一截时间,多付一笔账。但在那些容错率低的任务上,这笔成本通常值得:例如复杂合同审查、诉讼策略推演、程序风险排查、代码重构、长文校对、数据分析。
这些事情的共同点是:错一点,后面可能连着错一串。
但“想得深”并不等于永远更好。
人类的第一直觉,很多时候反而是最准、最快的。日常常识判断、危险情形下的即时反应、简单事实的确认,本来就不需要拉出系统 2 大动干戈。
机器也一样。你拿“1+1 是否等于 2”去喂深度思考模式,它可能绕半天,最后还给你一个看似周密却多余的答案。这不是聪明,而是火候不对。
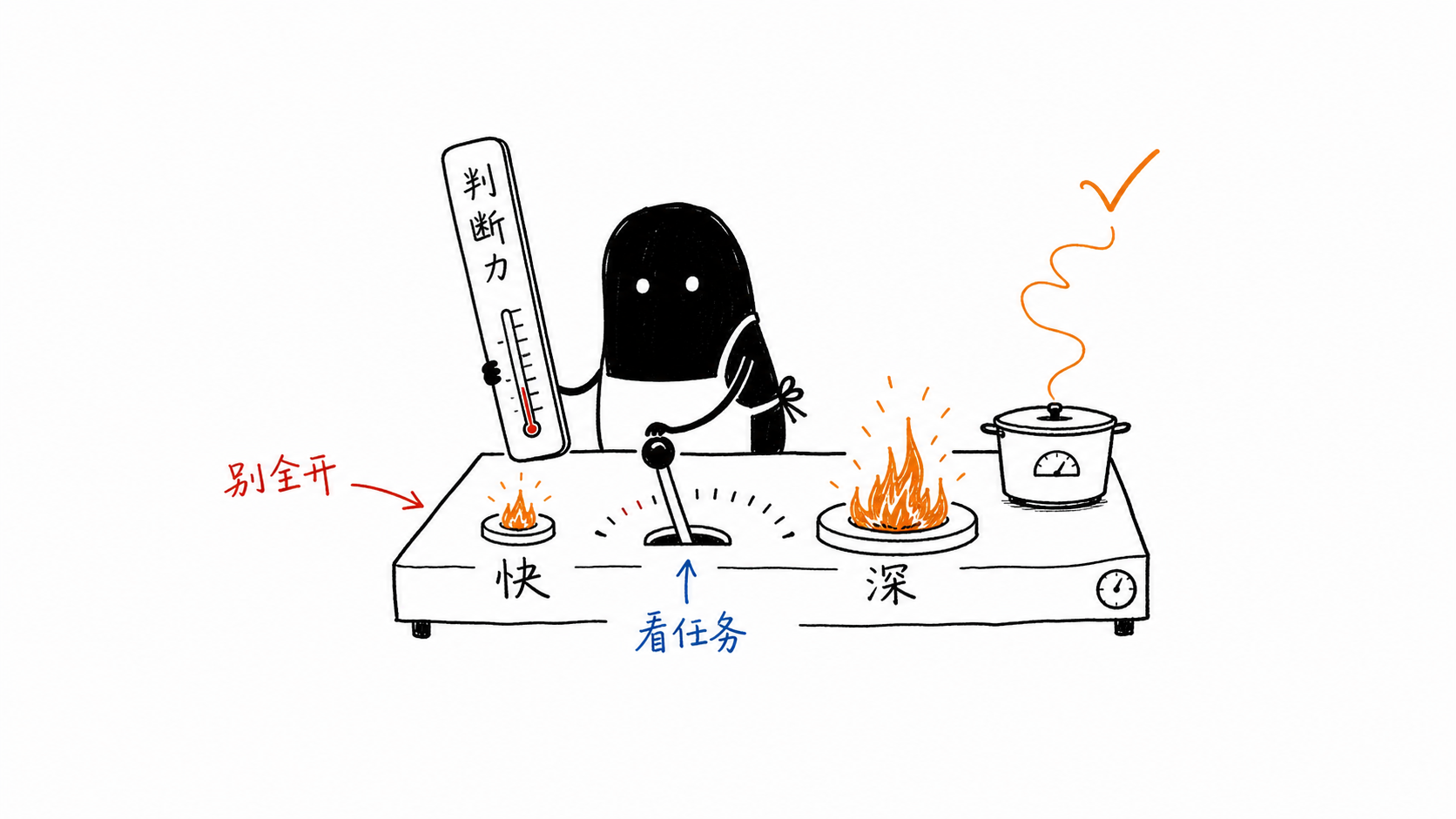
所以,第一组旋钮的诀窍很简单:该深则深,该快则快,杀鸡不必用牛刀。
第二个旋钮:用哪个脑子
这里有个最容易被混为一谈的地方:很多人以为“让它想得更深”就等于“让它更强”,其实这是两件事。
思考程度调的是功夫,模型选择换的是脑子。
思考程度,调的是模型在这一次任务里愿意花多少功夫。换模型,换的则是脑子本身:它的知识密度、推理上限、抽象能力、表达能力、工具使用能力,到底处在什么层级。
小模型可以开深度思考,旗舰模型也可以秒回。但这不意味着二者站在同一条起跑线上。
很多时候,强模型的普通回答,会比弱模型深思熟虑半天更好。原因也并不神秘:前者的“本事”原本就更厚,后者再努力,也很难临时突破自己的天花板。
快有两副面孔。
要看清这一点,得先拆开一个词:快。
一种快,是想都没想的冲动,是空的。它像一个人没读题就举手抢答,气势很足,但答案未必靠谱。
另一种快,是棋手扫一眼棋盘就知道落子,是资深律师听完案情就能大致判断争点。那种“不假思索”的背后,是成千上万小时的慢功夫,被压缩、固化成了直觉。
这种快,不是慢的反面,而是慢的结晶。
强模型的秒回,更接近“庖丁解牛”。
庄子笔下的庖丁说得透。他刚开始解牛时,“所见无非牛者”,满眼都是一头完整的牛,无从下刀;练了三年之后,“未尝见全牛也”;到最后,则是“以神遇而不以目视”,闭着眼也能游刃有余。
那把快刀,是从笨功夫里一刀一刀磨出来的。
模型也是这个道理。高水平模型的“秒回”,更接近训练阶段沉淀出来的能力压缩。它不是临时偷懒,而是大量训练和反馈之后,把许多判断固化进了权重里。
所以,回到那道高考卷:只把 Sonnet 4.6 的 effort 从 Low 拉到 Max,未必就够。那条回复真正点破的是:有些题先得换一颗更强的脑子,再谈让它多努力。
别让“默认”替你做主
讲到这里,就轮到最该提醒的习惯了:别一上来就用默认,更别图省事永远停在快速挡。
默认快速模式,适合闲聊,不适合正经活儿。
不少工具的默认选项,其实是为了省成本、提速度、降低等待感。它适合闲聊、润色、发散想法,也适合回答很多轻量问题。
但一旦任务进入“错了会有后果”的范围,默认快速模式就可能埋雷。比如让 AI 帮你起草一份合同、审一份起诉状、判断一个程序期限、梳理一个复杂案情,如果它仍然用系统 1 的方式张口就来,你得到的可能不是帮助,而是一份包装得很流畅的风险。
自动模式有价值,但不能完全外包判断。
也有些工具的默认选项是“自动”:模型自己判断这道题该想多深,再决定花多少功夫。
某种意义上,它是在替你做“火候”的判断。这恰恰对应卡尼曼说人脑很容易失灵的地方:系统 1 什么时候该把活儿交给系统 2,那个把关动作,人经常做不好。
机器正在学着替自己,也替你守好这道关。但至少现在,这道关还不能完全外包。你仍然得知道什么时候该信任自动,什么时候该夺回方向盘。
具体到法律工作,多数时候要更偏向深度思考。
对法律人来说,客观讲,大部分正经工作都应该偏向深度思考。
但这也要看活儿的分量。一份普通咨询回复、一段条款润色、一篇普法文章提纲,默认模式或中等思考程度也许足够;一桩疑难复杂案件、一次再审策略推演、一份会被提交法院的关键文书,就应当把思考程度拉高,必要时还要换更强的模型。
一份起诉状初稿,和一桩最高法再审的攻防策略,本来就不该用同一挡火候去煨。
真正拉开差距的,是判断力
说到底,旋钮越来越多,并没有把选择从人手里拿走,只是把选择挪了个地方。
过去,你主要判断的是:这个问题要不要问人、问谁、查哪本书、翻哪条法条。现在,你还要判断:该用哪个模型、开多少思考、给多少上下文、什么时候要求它复核、什么时候必须自己下场。
人与人使用 AI 的差别,很大程度上,就是这种判断力的差别。
判断 AI 的答案,先要自己有底。
AI 的答案通常很顺。越是顺,越容易让人放松警惕。
真正重要的是,你能不能在第一时间嗅出某处“不对劲”:这个案例是不是编的?这条规则是不是过时了?这个推理是不是跳步了?这个结论是不是忽略了程序阶段?这个建议是不是看起来很漂亮,实际落不了地?
没有自己的底子,就很难判断 AI 的答案到底是帮手,还是陷阱。
判断该怎么用 AI,本身也是专业能力。
会不会提问,当然重要。但更重要的是,会不会安排任务。
哪些问题适合让 AI 先发散,哪些问题适合让 AI 严格按证据归纳,哪些问题必须让 AI 列出不确定性,哪些问题只能让 AI 做辅助,最后结论必须由人来承担责任。
这些都不是按钮本身能替你完成的。
人的判断力,本身就是一种被慢功夫喂养出来的“快”。我们用它去驾驭 AI 的两个旋钮,而它自己,恰恰是最难用旋钮调出来的东西。
一个挥之不去的隐忧
但顺着这条线想下去,会撞上一个让人不安的问题:如果深度思考这件事,越来越多地被 AI 替我们代劳,人会不会逐渐丧失深度思考的能力?
判断力建立在“自己真的深想过”的基础上。
这不是杞人忧天。
判断力并不是凭空长出来的。它建立在你自己真正读过、想过、写过、错过、返工过、被质疑过的基础上。正是那些慢、笨、累、反复无常的过程,慢慢磨出了直觉。
可如果那个“深想”的环节被外包出去,久而久之,我们赖以驾驭 AI 的判断力,会不会反倒先一步萎缩?
年轻人的“笨活”梯子,正在被抽走。
这件事已经在加速。
这两年,文科背景的实习生越来越难找到对口工作。很多过去由年轻人一点点积累的基础任务,正在被 AI 工具替代:资料整理、会议纪要、检索归纳、初稿撰写、格式转换,甚至电脑上的许多事务性杂活,也开始被 Codex、Claude Code/Cowork 这类代理工具,乃至各种能操控本地电脑的 agent 接管。
问题是,过去的年轻人正是靠这些笨活、杂活,一点一点攒下经验,磨出直觉,长出判断力。
当这架梯子被抽走,下一代人的“经验之山”,又该从哪里垒起?
我没有答案。但隐隐觉得,这才是比“选哪个模型”更要紧、也更难的那道题。
说到底,是火候
中文里有个词,把这一切说尽了,叫火候。
火候讲的从不是火大火小,而是恰到好处:该猛则猛,该文则文,分寸全在那一念的拿捏。
选模型、调思考,是火候;什么时候信任 AI、什么时候自己上手,是火候;在这个一切都急着被外包出去的时代,懂得有些功夫必须留给自己亲手去练,也是火候。
真正的高手,不是把每一档都开到 Max,而是知道什么时候根本不必开。
旋钮的用法,三两下就学会了;可决定该拧哪个旋钮的那点判断力,是一辈子的功夫。这门手艺,我们在学,机器也在学。只盼我们别在学会用它的同时,也弄丢了那个配得上用它的自己。